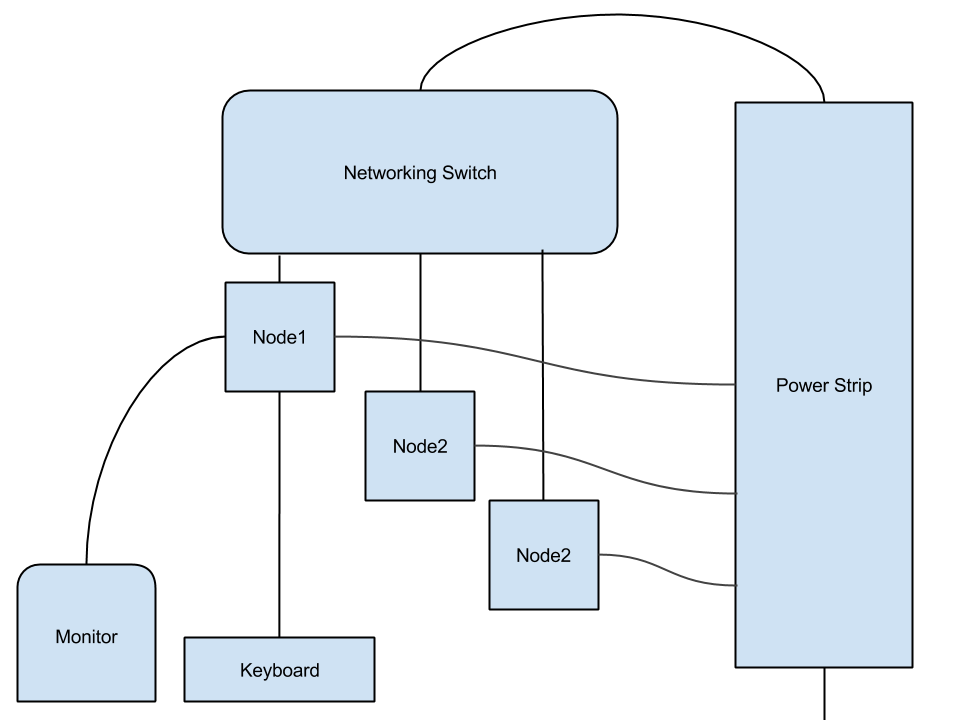
My girlfriend made the bold decision of getting me what's currently considered a bit of a "controversial" device-- the Steam Link. While I had more or less directly asked for one, or at least hinted at it with my Amazon wish list in the weeks prior, I'd be lying if I said I wasn't a little nervous about the prospect, especially after watching Super Bunnyhop's very thorough review.

Thankfully though, upon initial setup I'm happy to report that I didn't experience any of the potential hurdles. As a seasoned technologist (or whatever you would call me), I'm very wary of the term "Plug'n'play", knowing fully that anything can go wrong. This was evidenced by the fact that I laughed aloud at the idea of the steam link's "quick start" manual that is literally two images of how everything connects, and a link to link.steampowered.com. Keep in mind that I've never once used "Big Picture Mode", or streamed from any device onto another. Surprisingly though, despite my expectations, within 10 minutes, I was easily playing Metal Gear Rising on my downstairs TV with no lag to report of... What is this wizardry?
It's possible that I faced little impedance because I had the tools for the job-- the recommend wired Xbox 360 controller and a handy wireless touch keyboard that I keep around for my Raspberry Pi projects. I'd particularly recommend scoring a wireless touch keyboard because it allows you to have a mouse and keyboard for interfacing at the cost of only a single USB port. Though I must say, for my experience of playing Rising, Rogue Legacy and then buying two games on sale, I only used it to move my mouse icon out of the way from the screen on Rising (an in-game problem, no fault on the device), and to more conveniently enter my credit card information.
Bunnyhop's review gave me the impression that knowing what games were "out of the box" compatible with the Steam Link would be a gamble each time. However, I can thankfully report that's not the case. The UI has this great system for every game you select that shows the controller type and then a check or arrow depending on whether the game is installed. Most importantly, the UI will only display the controller icon if the game can play with the controller natively, i.e. no configuration needed. For example, Rising and Rogue Legacy show the controller icon, whereas a game that can be configured with a controller just shows a keyboard by default. Some may not care for this non-inclusiveness, but after busting my skull trying to get controllers working for games that brag some kind of controller support (Dead Rising 2), it's nice to know that you're entering at your own risk. In fact, I wish my PC version of steam did this by default!
That being said I've not yet to experiment playing with games that require any configuration, or play with any emulators. I will report back with those inevitable frustrations.
Even when purchasing games via the Link, it was kind enough to inform me that I was purchasing a game that was intended for keyboard and mouse. I feel like this information was contained in Bunnyhop's great review, but it's really something you may not notice until you experience it for yourself-- and it made a big difference for me.
When interfacing menus with the controller, there's a surprising amount of easy to access features, whether you're just navigating within your library/store or from in-game. Particularly appealing to me is the dichotomy of "My Game" for each title, which contains all of the personal stuff, like screenshots, and then below that all of the other community resources. I've not tried chatting or web browsing, but the option is there!
Now, regarding graphic quality. I'm really glad I chose to play Rising first, as I can't think of a game in my library that would be more of a struggle to stream onto a downstairs TV than this one. However, I was immediately impressed by the quality. Much like how the pre-rendered cutscenes in Rising look like real gameplay (in my humble opinion), so does the stream on your TV match the real thing! I think we all know what the artifacts of streaming look and feel like, and while I'm fairly naive in the streaming circuit, I definitely feel like you could fool me with this one! That's so far, but I definitely feel like Rising and Rogue Legacy were good litmus tests for being such different games. I'll continue to update with my findings and frustrations, but for now I'm very satisfied and would highly recommend the steam link to anyone that wants to share some of their PC love downstairs on the couch.

Thankfully though, upon initial setup I'm happy to report that I didn't experience any of the potential hurdles. As a seasoned technologist (or whatever you would call me), I'm very wary of the term "Plug'n'play", knowing fully that anything can go wrong. This was evidenced by the fact that I laughed aloud at the idea of the steam link's "quick start" manual that is literally two images of how everything connects, and a link to link.steampowered.com. Keep in mind that I've never once used "Big Picture Mode", or streamed from any device onto another. Surprisingly though, despite my expectations, within 10 minutes, I was easily playing Metal Gear Rising on my downstairs TV with no lag to report of... What is this wizardry?
It's possible that I faced little impedance because I had the tools for the job-- the recommend wired Xbox 360 controller and a handy wireless touch keyboard that I keep around for my Raspberry Pi projects. I'd particularly recommend scoring a wireless touch keyboard because it allows you to have a mouse and keyboard for interfacing at the cost of only a single USB port. Though I must say, for my experience of playing Rising, Rogue Legacy and then buying two games on sale, I only used it to move my mouse icon out of the way from the screen on Rising (an in-game problem, no fault on the device), and to more conveniently enter my credit card information.
Bunnyhop's review gave me the impression that knowing what games were "out of the box" compatible with the Steam Link would be a gamble each time. However, I can thankfully report that's not the case. The UI has this great system for every game you select that shows the controller type and then a check or arrow depending on whether the game is installed. Most importantly, the UI will only display the controller icon if the game can play with the controller natively, i.e. no configuration needed. For example, Rising and Rogue Legacy show the controller icon, whereas a game that can be configured with a controller just shows a keyboard by default. Some may not care for this non-inclusiveness, but after busting my skull trying to get controllers working for games that brag some kind of controller support (Dead Rising 2), it's nice to know that you're entering at your own risk. In fact, I wish my PC version of steam did this by default!
That being said I've not yet to experiment playing with games that require any configuration, or play with any emulators. I will report back with those inevitable frustrations.
Even when purchasing games via the Link, it was kind enough to inform me that I was purchasing a game that was intended for keyboard and mouse. I feel like this information was contained in Bunnyhop's great review, but it's really something you may not notice until you experience it for yourself-- and it made a big difference for me.
When interfacing menus with the controller, there's a surprising amount of easy to access features, whether you're just navigating within your library/store or from in-game. Particularly appealing to me is the dichotomy of "My Game" for each title, which contains all of the personal stuff, like screenshots, and then below that all of the other community resources. I've not tried chatting or web browsing, but the option is there!
Now, regarding graphic quality. I'm really glad I chose to play Rising first, as I can't think of a game in my library that would be more of a struggle to stream onto a downstairs TV than this one. However, I was immediately impressed by the quality. Much like how the pre-rendered cutscenes in Rising look like real gameplay (in my humble opinion), so does the stream on your TV match the real thing! I think we all know what the artifacts of streaming look and feel like, and while I'm fairly naive in the streaming circuit, I definitely feel like you could fool me with this one! That's so far, but I definitely feel like Rising and Rogue Legacy were good litmus tests for being such different games. I'll continue to update with my findings and frustrations, but for now I'm very satisfied and would highly recommend the steam link to anyone that wants to share some of their PC love downstairs on the couch.